本文主要针对论文“MapReduce: Simplified Data Processing on Large Clusters”进行了概括及总结。
目的
- 作业输入数据的规模较大
- 这些任务的运行时间受限,因而需要利用数据中心内的海量节点进行分布式计算
- 容错及异常处理较复杂且维护成本较高
解决方案
提出了MapReduce架构,将任务的计算流程分为Map和Reduce两个阶段,方法均由用户提供。
- MAP
- 输入:input pair, e.g. (1, “hello world”) in Word Count
- 输出:a set of intermediate key/value pair, e.g. [(“hello”, [“1”, “2”]), (“world”, [“1”])] in Word Count
- REDUCE
- 输入:an intermediate key + a set of values for this key,如MAP过程的输出
- 输出:合并上述values,通常最后为zero or one value
- 案例
- Distributed Grep, Count of URL Access Frequency
执行流程
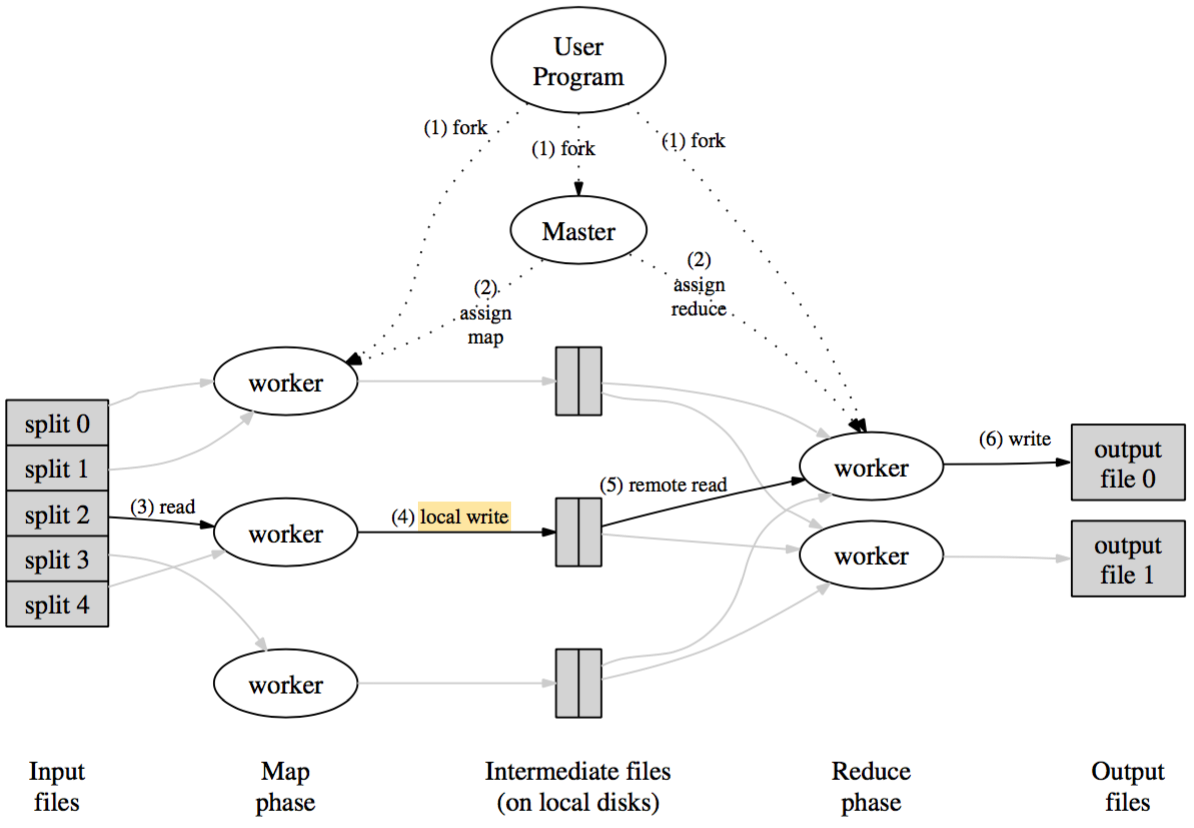
- 将输入数据切分为M块,单块大小为16-64MB;
- 128MB,适用于大文件
- 用户按需求自定义
- 选取M+R个状态为idle的worker分配任务;
- map任务尽量在split块对应节点或其“附近”执行(same network swith)
- Master节点维护任务状态信息(idle, in-progress, completed),HTTP通信
- 若W为用户期望使用的worker数量,一般来说,M通常远大于W,R通常为W的几倍
- M和R由用户指定,用户根据需求估计,R的数量跟业务相关
- W为用户申请的并发资源量
- Map Worker读取输入split,对每个pair执行MAP程序;
- Map读split文件的方式
- 没有对文件实际的切割,只是记录了要处理的数据的位置和长度
- map数量与split 数量,splitSize=max(minSize, Math.min(goalSize, blockSize))
- minSize,用户指定的最小切分
- blockSize,HDFS块大小(128MB)
- goalSize=totalSize/numSplits,numSplits,用户期望的map数量
- 若splitSize大于blockSize,说明需要将多个block合成到一个split,这样有部分block数据需要通过网络读取
- 若splitSize小于blockSize,说明需要将一个block拆成多个split,增加Map任务数
- 假设splitSize是默认的64M,现在输入包含3个文件,这3个文件的大小分别为10M,64M,100M,那么这3个文件会被分割为10MB,64MB,64MB,36MB
- 通常splitSize 就等于blockSize的默认值
- 一条数据跨split(block),只要不是第一个split,忽略第一条数据
- 合并小文件,避免block对内存的浪费
- 提供了默认的读取类型,如”text”, “key-value pair”,各类型能够确定数据切分的正确性
- 用户自定义reader接口,从数据库,内存中读取数据
- 图中表示实际读取的情况

- Map读split文件的方式
- Map任务将中间结果缓存至内存中,并定期溢写到磁盘(80%);
- 划分函数(partitioning function)将中间结果分割为R片区域(region)
- 划分函数利用hash,例如{hash(key) mod R},{hash(Hostname(urlkey)) mod R}
- 划分数量与Reduce任务数量相同
- Region内部的中间结果默认按key增序排列,方便用于随机访问,排序,有时可能说外排序
- 合并函数(Combiner)在map阶段部分合并key相同的value,本质与Reduce相同,减少网络带宽消耗
- 缓存结果在磁盘中的位置会被传递至Master节点,后续用于Reduce过程
- 用户生成的临时辅助文件需要用户自定义保证正确性(原子性,幂等性)
- map重算,用户处理还是框架处理
- 划分函数(partitioning function)将中间结果分割为R片区域(region)
- Reduce worker从Master处获取文件位置信息,RPC读取map worker中的中间结果
- 所有结果读取后按key进行排序,key值相同的数据被合并
- 若排序过程中数据量过大需采用外部排序;
- Reduce woker逐个处理每个中间结果,对于每个key值及其对应的value set,调用reduce程序
- Reduce的启动时机,70%
- Reduce Task启动过早,长时间占用slot,资源利用率低
- Reduce Task启动过晚,Map-Reduce串行执行,拖延任务运行时间
- 通过已经运行完成的Map Task运行时间估算正在运行的Map Task的剩余运行时间,当Map阶段剩余时间达到一定值后,才开始调度Reduce Task
- 所有map及reduce任务完成后,master唤醒并返回用户程序,生成R个输出文件
上述Map及Reduce的流程可以概括为:
- Map任务:从GFS读取数据-执行MAP程序-combine过程-输出中间结果至本地磁盘
- Reduce任务:从map节点读取中间结果-根据key进行排序-执行REDUCE程序-输出结果至GFS
容错控制
- Master节点故障
- 定期checkpoint
- 代价较高
- 只有单节点在线,Master故障后Client会一直重连
- 定期checkpoint
- Worker节点故障
- Master定期ping每个worker,若无响应,则标记为故障节点
- 故障节点中的map任务需重做状态为运行中(in-progress)及已完成(completed)的,因为中间结果无法读取
- 重做map任务后,所有reduce任务均被通知,数据未读取完成的任务要重新读取
- 大部分情况下,不要影响Reduce,Reduce重做代价较高
- 故障节点中的reduce任务只需重做状态为运行中(in-progress)的,已完成的结果已被存值GFS
- Straggler
- 当一个MapReduce作业即将完成时,master为剩余状态为in-progress的任务创建多个相同备用任务,任务对应的副本中其中有一个完成即可
- 预测执行
- Map和Reduce均有,比例控制
- Map和Reduce的输出一致性保存
- 异常数据记录
- 程序中的bug可能会导致在读取某部分数据时产生异常,阻止作业继续运行
- bug不易修复;由第三放库引起;统计分析可忽略
- 提供直接跳过这部分数据(record)的功能
- 每个worker配有一个信号处理程序(signal handler),捕捉segmentation violations & bus errors,暂存与MapReduce上下文中
- 若由用户代码生成,signal handler会向master发送特定UDP信息,若master收到多次提醒,则在该任务重新执行时提示其跳过
- 数据的record与split之间的关系:record指某一条具体数据,具体引起程序崩溃的record位置会被记录,skip bad record